Retrieval Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a cutting-edge approach in AI that combines the power of large language models (LLMs) with external data retrieval to deliver accurate and context-aware responses. Instead of relying solely on pre-trained knowledge within a model, RAG retrieves relevant information from external sources, such as databases or APIs, and uses it to generate informed answers. This technique bridges the gap between the static knowledge of AI models and the dynamic nature of real-world data, making it ideal for applications like customer support, research assistance, and domain-specific queries. By blending retrieval and generation, RAG ensures responses are both precise and up-to-date.
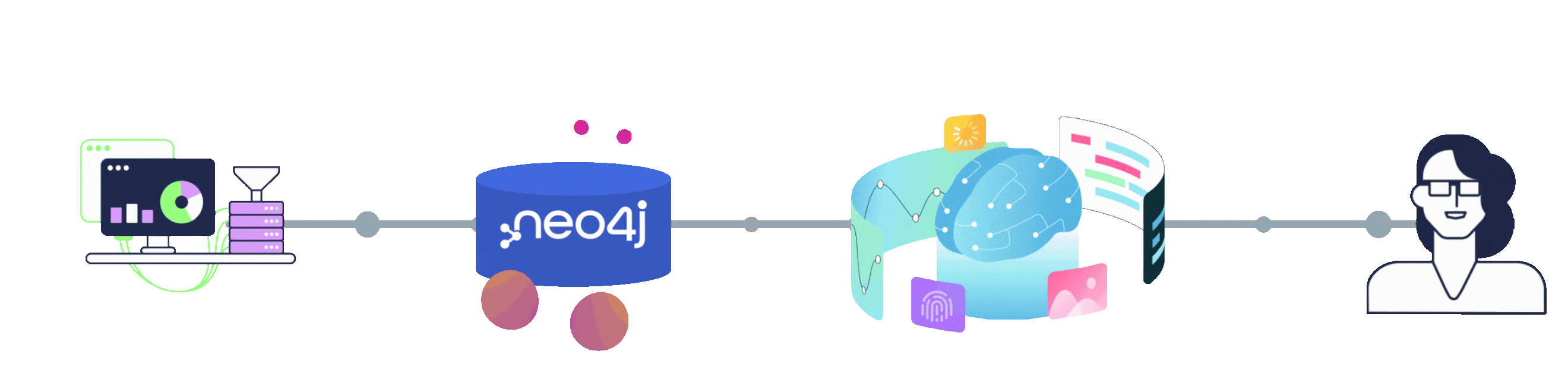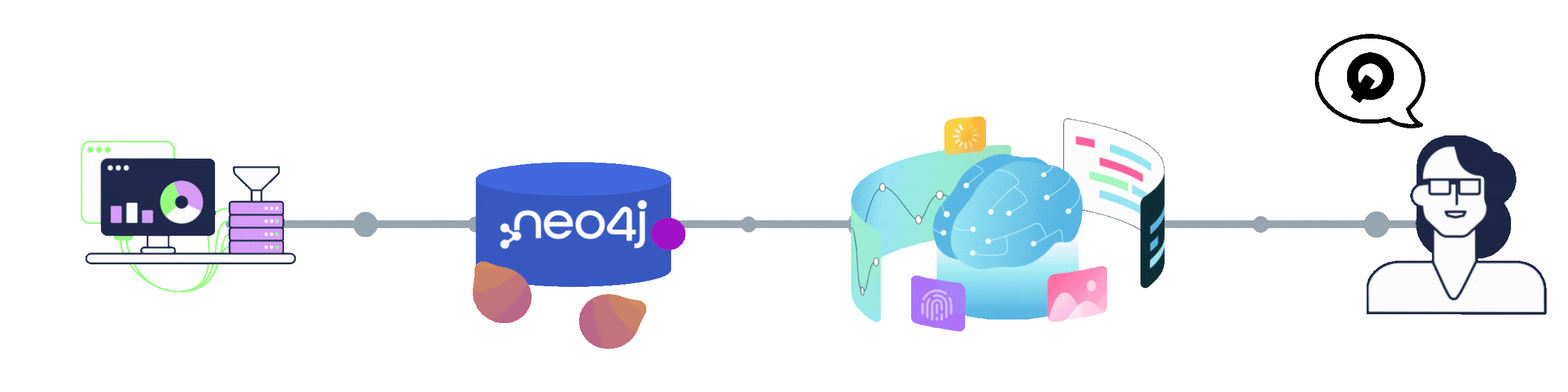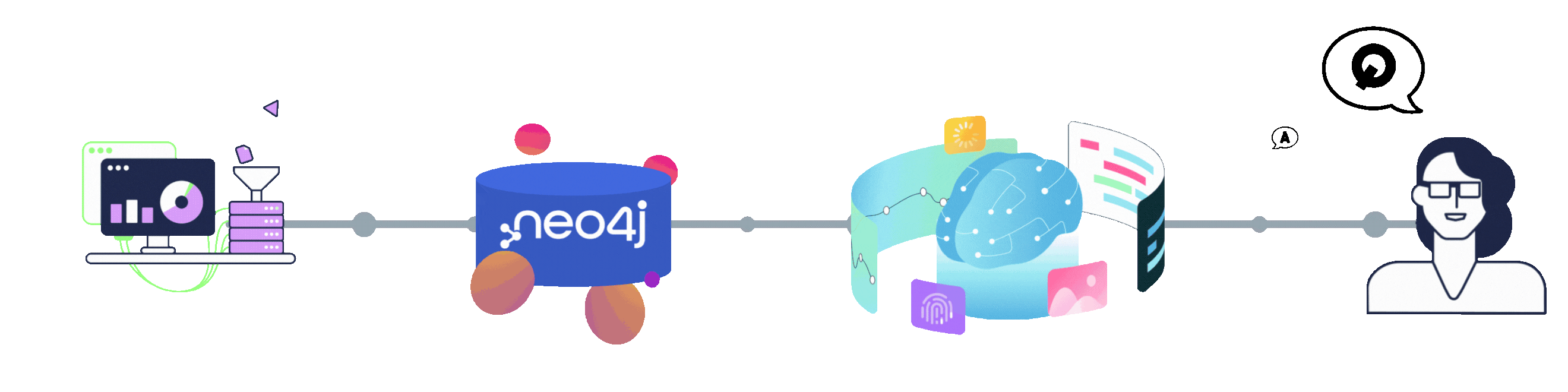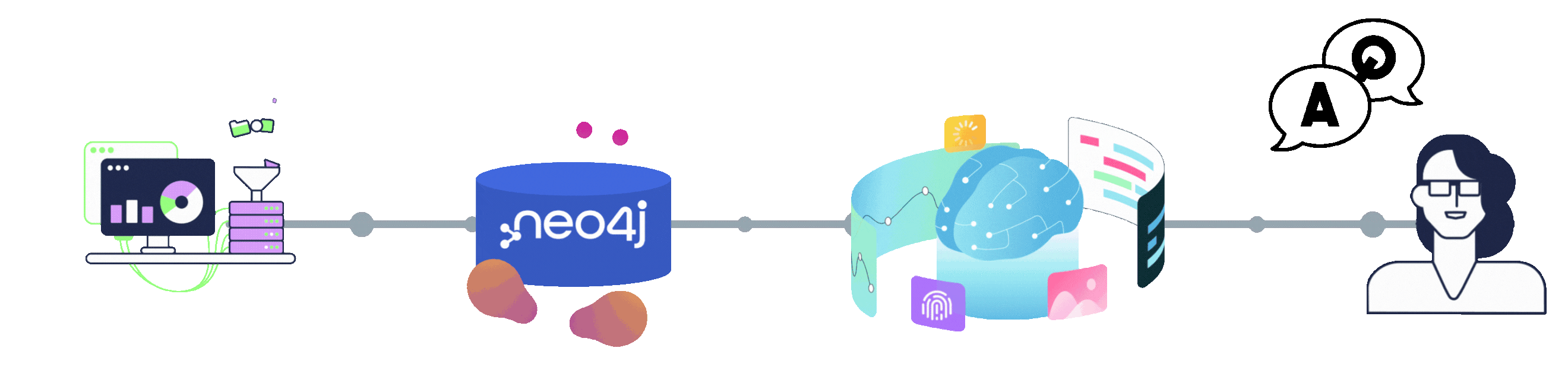
Tesla Example
Simple Retrieval
In this example, we demonstrate how to build a Retrieval-Augmented Generation (RAG) solution using Neo4j, LlamaIndex, LangChain, and OpenAI and FastAPI technologies, with the API hosted on Seenode. The process starts by chunking documents using LlamaIndex, which breaks the content into manageable pieces. These chunks are then stored in Neo4j as nodes and embedded using OpenAI's large embedding model to capture semantic meaning. LangChain's Neo4j integration is used to create a retrieval chain that efficiently fetches relevant information for a given query. Finally, OpenAI's GPT-4-turbo model processes the retrieved data to generate a coherent, context-aware chat response. This streamlined pipeline combines the strengths of structured data storage, advanced embeddings, and natural language generation.
For this example we take a few sample web pages relating to Tesla Inc. to form a knowledge base, ingesting these into our Neo4j database and made accessible via the chat interface below.


Ingestion and Embedding
The ingestion process begins using LlamaIndex, breaking documents into chunks. These chunks are stored in Neo4j as nodes, with relationships preserving their order and context within the original document, enabling structured and sequential querying. Each node is then embedded using OpenAI’s large embedding model, creating rich vector representations that capture semantic meaning. This approach ensures the data is organised, context-aware, and easy to retrieve for precise, relevant answers.

Building a Retrieval Chain
The next step involves building a retrieval chain using LangChain, which taps into the vector embeddings stored in Neo4j. This retrieval process combines vector similarity, graph querying, semantic search, and keyword matching to find the most relevant responses. The vector similarity search identifies the top N results based on contextual relevance; while the graph query expands the results by retrieving neighbouring nodes, preserving the document's structure and providing additional context. This layered approach ensures the system not only finds precise matches but also includes surrounding information for a more comprehensive response.
Additional Components
There are a number of additional key components that make the simple solution work.



Seenode Hosting
Seenode is used to host the FastAPI application, which powers the LangChain retriever, on its free service tier. It connects directly to the GitHub repository, enabling automatic deployments and updates whenever changes are pushed. This provides a cost-effective way to keep the API accessible, scalable, and up-to-date with the latest code.
Github
GitHub plays a crucial role in managing the codebase for the solution, enabling version control. By linking the repository to Seenode, any changes made in GitHub trigger automatic deployments, ensuring that the latest updates are reflected in the hosted FastAPI application. This seamless integration streamlines the development process and ensures the API remains up-to-date.
Data Streaming
Using a streaming setup that connects OpenAI, LangChain, and FastAPI for real-time responses. User queries flow through FastAPI, which retrieves data via LangChain and generates a response with OpenAI. This information is streamed from the backend to the Wix frontend, ensuring a fast and interactive user experience.. The entire flow ensures a smooth and interactive experience across the application.
User Query
Use the chat input below or the example questions to query the information in the database.
...